今まで、赤黒木・AVL木・2-3木 と紹介してきました。 本ページでは、いよいよB木の説明に入ります。 B木は2-3木を一般化し、 各ノードが最大で m 本の枝を持てるようにした平衡木です(m≧3)。 要素の検索・挿入・削除などの操作が、 いかなる場合でも \(O(\log n)\) の計算量で行えます(\(n\) は要素数)。 また、赤黒木やAVL木と異なり、 全ての葉から根までのノード数が等しく完全にバランスしています。 どんなところで使われているかというと、 B木を基礎としたアルゴリズムがファイルシステムやデータベースの実装に使われています。
このページはたぶん、 他のサイトよりやさしくB木について解説しています。 特に削除操作などは解説していないサイトも多いですが、 本ページではちゃんと解説しています。 もし、このページの内容が難しいと感じるようなら、まず、 AVL木 や 2-3木 のページを読んでみてください。
それでは、Haskell でB木を使った ツリーソート を実装しましょう。 もちろん、B木を使ったツリーソートも安定ソートです。Haskell による B木を使ったツリーソートの実装は以下のようになります。 (Java による実装をお望みの方は こちらのページ へどうぞ。ツリーソートではありませんが、 B木の実装のサンプルを示してあります)
B木の悪い噂を知っている人は、 「えっ!?これだけ?」と思うかもしれません。 B木の実装は複雑で大変だと聞いていたのに、 これではむしろAVL木や2-3木より簡単じゃないかと言いたいでしょう。 私も実装してみてびっくりしました。 簡略化だとかリファクタリングだとかそんなチャチなもんじゃあ断じてねえ! Haskell の記述能力の片鱗を味わったぜ…といったところでしょうか(^^; でも実は、 B木のアイディアが言われているよりずっとシンプルなのが本当のところです。
さて、2-3木によるツリーソートがかなり高速だったので、 B木によるツリーソートはさぞ凄かろうと思うかもしれませんが、 残念ながらB木によるツリーソートの性能はそれほどではありません。 理由については後で触れますが、 オンメモリで使う場合、 B木は実はAVL木などの2分探索木より遅いことが知られています。 あくまでもB木は、 ファイルシステムやデータベースのような遅いブロックデバイス上で使うときに威力を発揮します。
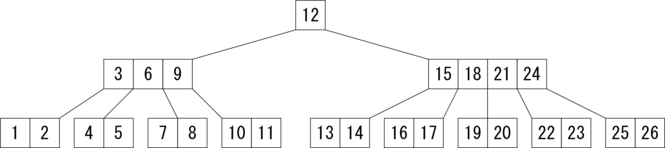
それでは、B木に関して説明しましょう。以下の図で、 1,2 や 3,6,9 などが入っている箱のことをノードと言います。 ノードから出ている下側の線を枝と言います。 枝の先にあるノードのことを元のノードに対して子と言います。 子から見ると、元のノードを親と言います。 B木のノードは最大で m 本の枝を持ちます(m≧3)。 そして、枝と枝の間には要素が1つあります。 つまり、 1つのノードに要素が最大で m - 1 個割り当てられることがあるわけです。 m のことをB木のオーダーと呼びます。
|
|
B木は以下の条件を満たす多分探索木です。
ここで、[m/2] は m/2 の小数点以下を切り上げる演算です。
根(root)とは 12 が割り当てられている最上位のノードのことで、
葉とは空のノード(Empty)のことです。
1,2 や 4,5 が割り当てられているノードの下には本来枝があるのですが、
簡略化のため図示はしていません。
空のノード(Empty)はこれらの枝の先にあると考えます。
各枝の先にある木構造のことを部分木と言います。
最大の部分木はB木自身です。
B木の最後の条件は重要で、赤黒木やAVL木と違って、
B木が完全にバランスしていることを示しています。
B木で要素を検索するには、まず根から探し始めます。 例えば、図1.で 4 を探す場合、4 は 12 より小さいので、 左の部分木に含まれているはずです。そこで、左の枝の先のノードを調べます。 4 は 3 より大きく 6 より小さいので、 3 と 6 の間にある部分木に含まれているはずです。 そこで、3 と 6 の間の枝の先のノードを調べます。 すると、たどり着いたノードの中に 4 が見つかります。 もちろん、葉までたどり着いて目標の要素が見つからない場合もあります。 その場合は、B木に目標の要素は含まれていないことが分かります。
では、B木の挿入操作について説明します。 赤黒木やAVL木同様まず要素が既に登録されているかどうか検索します。 既にあればそのノードを置き換え、無ければ挿入することになります。 すなわち、挿入は常に最下層のノードで開始されます。
挿入にはアクティブなノードを挿入します。アクティブなノードとは、
他のノードに触れると反応して木の形を変えるノードのことです。
挿入時のアクティブなノードは挿入する要素を1つ持ち、
部分木(枝)を2つ持ちます。
部分木は最初は空(Empty)です。
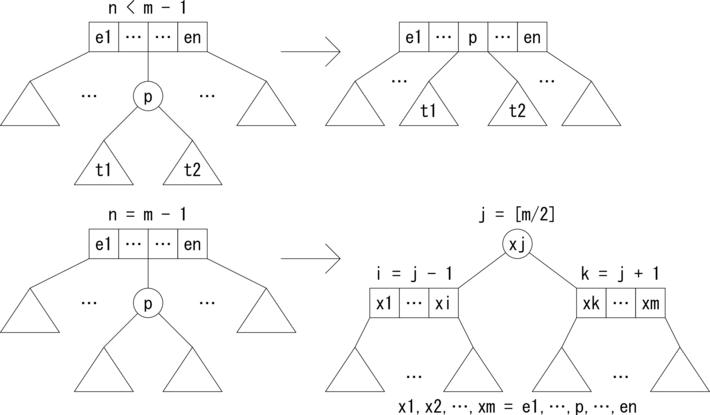
図2.にB木の挿入パータンを示します。 通常のノードを四角で、アクティブなノードを丸で表しています。 p が挿入される要素です。三角は部分木を表しています。まず、 アクティブなノードの親ノードの要素数 n が n < m - 1 の場合ですが、 親ノードの要素と枝を1つ増やしてアクティブなノードを取り込みます。 アクティブなノードが無くなり安定します。
|
次に、
アクティブなノードの親ノードの要素数 n が n = m - 1 の場合ですが、
アクティブなノードを親ノードに取り込むと、
要素数が m、枝の数が m + 1 になり、
B木の条件を満たさなくなります。
そこで親ノードを分割し、アクティブなノードを生成します。
新たにアクティブなノードが生成されるので、
さらに上位のノードに対して挿入操作を再帰的に繰り返すことになります。
そして根までアクティブなノードが到達した場合は、
アクティブなノードを通常のノードに変換して新たな根にします。
説明が前後しますが、
空(Empty)のB木にノード挿入する場合も、
アクティブなノードを通常のノードに変換し根にします。
図はたくさんある枝の特定の1本を処理する場合の例示になっています。 全てのパターンを列挙することは不可能だからです。 読者は個々の具体的ケースを想像で補う必要があります。 よく分からないという場合は、 2-3木のページ を参照してください。 2-3木はB木の m = 3 の場合です。2-3木のページでは、 2-3木の全ての挿入パターンを列挙してありますので、 これを手がかりに想像すると分かりやすいと思います。
具体的な挿入の例を m = 3 のケースで示しておきましょう。 m = 3 なので [m/2] = 2 です。以下のようになります。
左端において、赤で示したアクティブなノード 1 が挿入される例です。
ここでは、三角は Empty だと思ってください。
もちろん、部分木とみなすことも出来ます。
ノード 2,3 の要素数 n は 2 であり n = m - 1 なので、
アクティブなノードに触れると分割され、
新たにアクティブなノード 2 が生成されます。
2 は上位のノード 4 に挿入されることになります。
ノード 4 の要素数 n は 1 であり n < m - 1 なので、
アクティブなノードを取り込んで安定します。
もう1つ、アクティブなノードが根に到達した場合の例をあげておきます。 アクティブなノードが根に到達した場合、 アクティブなノードをそのまま通常のノードに変換して新たな根にします。 このとき、木の高さが1段増えることになります。
気がついた人もいると思いますが、
B木の挿入では赤黒木やAVL木のような回転の操作がありません。
回転は部分木の高さを変えてしまうので木のバランスが変化します。
B木はバランスの状態を全く変えないので、
最初の木がバランスしていれば最後まで完全にバランスが取れています。
そして最初の木は空(Empty)ですから、
バランスは取れていると見なせます。
そのためB木は完全にバランスしているのです。
B木はソートのための技術というよりもファイルシステムやデータベースの基盤技術です。 そこでここでは、そうした利用シーンにより近い、 削除操作も含んだB木によるマップ(連想配列)の実装を見てみましょう。
ただし、削除操作は最下層のノードで開始されるものと見なして説明します。 内部ノードでの削除も最下層のノードでの削除に帰着できるからです。 内部ノードでの削除の具体的な説明はコードを読むことで代用してください。 基本的考え方は 赤黒木 や AVL木 と同じです。口で説明しても混乱すると思いますので、 コードで確認するのが一番と思います。 Haskell なんて分かんねーよ、という人は こちらのページ へどうぞ、Java による実装を紹介しています。
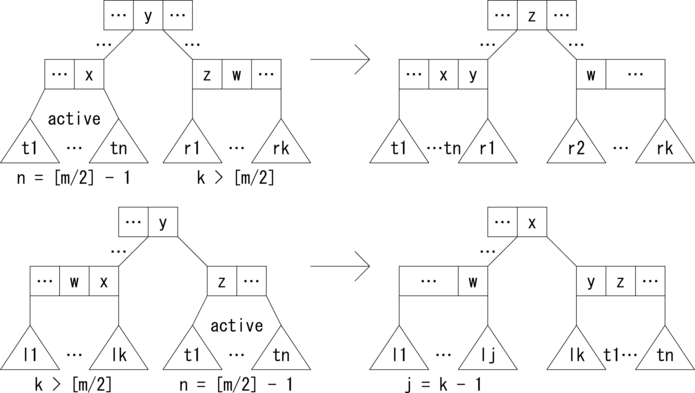
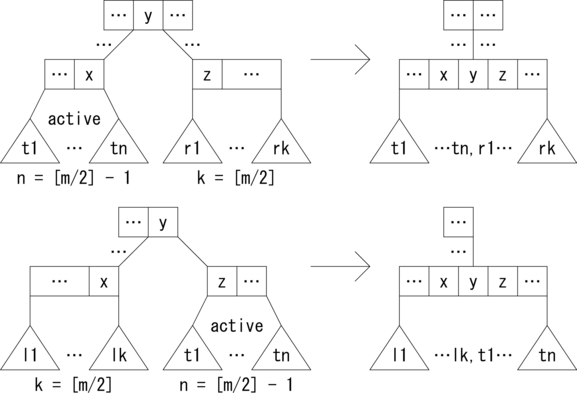
始めに、[m/2] 本より多い枝を持つノードからの削除ですが、 これは単純に対象の要素と枝を削除することで完了です。 しかし、[m/2] 分岐のノードから要素と枝を削除すると、 枝の数が [m/2] より少なくになってB木の条件を満たさなくなります。 そこで、このノードを削除時のアクティブなノードと見なして木を変形します。
変形の基本となる考え方はこうです。アクティブなノードと反応したら、 アクティブなノードの隣のノードから、余裕があれば、 つまり枝の数が [m/2] より多いノードだったら枝を1本分けてもらって、 アクティブなノードを [m/2] 分岐のノードに変換するというものです。 隣のノードに余裕がない場合、つまり枝の数が [m/2] だったら、 アクティブなノードと隣のノードを融合して、 m - 1 本以上 m 本以下の枝を持つノードに変換します。 このとき、親ノードで枝が1つ減ることになるので、 場合によっては親ノードがアクティブなノードになります。 その場合、再帰的に上位のノードで変形を繰り返します。 そして、根がアクティブなノードになった場合、 枝の数が 2 以上であれば、そのまま通常のノードとして扱い、 枝の数が 1、すなわち分岐が無くなったら、 そのノードは余分なので切り詰めて、子ノードを新たな根にします。
まずは、 アクティブなノードの隣のノードに余裕がある場合の削除パターンを示します。 n = [m/2] - 1 のキャプションのノードがアクティブなノード、 k > [m/2] のキャプションのノードが余裕のある隣のノードです。 余裕のあるノードからアクティブなノードへ、枝を1本移動します。 これにより、アクティブなノードが通常のノードに変換されます。
|
次に、 アクティブなノードの隣のノードに余裕がない場合の削除パターンを示します。 n = [m/2] - 1 のキャプションのノードがアクティブなノード、 k = [m/2] のキャプションのノードが余裕のない隣のノードです。 アクティブなノードと余裕のないノードを融合して1つにします。 これにより、融合したノードは通常のノードに変換されます。 このとき、親ノードで要素と枝が1つ減るので、 親ノードがアクティブなノードになる可能性があることに注意してください。
|
図はたくさんある枝の特定の2本を処理する場合の例示になっています。 全てのパターンを列挙することは不可能だからです。 読者は個々の具体的ケースを想像で補う必要があります。 よく分からないという場合は、 2-3木のページ を参照してください。 2-3木はB木の m = 3 の場合です。2-3木のページでは、 2-3木の全ての削除パターンを列挙してありますので、 これを手がかりに想像すると分かりやすいと思います。
具体的な削除の例を m = 3 のケースで示しておきましょう。 m = 3 なので [m/2] = 2 です。以下のようになります。
左端の赤で示したノードがアクティブなノードです。 要素が1つしか無い最下層のノード(つまり、枝は2本)において、 要素の削除を行うと生成されます。 m = 3 なので、アクティブなノードには要素がなく、枝は1本です。 アクティブなノードの隣のノード 2 の枝の数 k は 2 であり k = [m/2] なので余裕がありません。そこで、アクティブなノードと融合します。 すると、ノード 1 から枝が1つ減り、新たにアクティブなノードになります。 今度は、隣のノード 5,7 の枝の数 k は 3 であり k > [m/2] なので余裕があります。そこで、ノード 5,7 から枝を1本分けてもらいます。 すると、アクティブなノードは無くなり安定します。
もう1つ、アクティブなノードが根に到達した場合の例をあげておきます。 m = 3 の場合は、アクティブなノードの枝の数は常に1つなので、 アクティブなノードは余分に伸びていることになります。 そこで、アクティブなノードを切り詰めて、子ノードを新たな根にします。 このとき、木の高さが1段低くなることになります。
B木は m 分岐の多分木なので、計算量のオーダーが \(O(\log_2 n)\) の平衡2分木より速い。何故ならB木の計算量のオーダーは \(O(\log_m n)\) だからだ。 という話を聞いたことがある人もいるかもしれません(\(n\) は要素数)。 これは嘘ではありませんが、必ずしも正確ではありません。 実際に赤黒木やAVL木と比較してみれば、 明らかにB木の方が遅いことが分かるからです。
一例として、 平衡2分木とB木の検索における最悪比較回数を大まかに比較してみましょう。 平衡2分木の場合、1つのノードで必要な比較回数は2です。 たどる枝の数は要素数を \(n\) とした場合、 大まかに \(\log_2 n\) に比例しますので、 平衡2分木の検索における最悪比較回数は、 非常に大雑把に言って \(2\log_2 n\) ということになります。
一方B木は1つのノードに最大 m - 1 個の要素があります。 たどる枝の数は大まかに \(\log_m n\) に比例しますから、 B木の検索における最悪比較回数は、 少なく見積もって非常に大雑把に \(2(m - 1)\log_m n\) ということになります。
計算量のオーダーで比較すると、係数部分が無視されてしまうため、 一見するとB木の方が有利に思えますが、 係数 \(2(m - 1)\) がくせもので、 m = 3 で既にB木の比較回数が平衡2分木を上回ります。 つまり、B木の方が平衡2分木より遅いのです。
冷静に考えるとこれは当然で、 平衡2分木がほぼ完全に2分探索であるのに対して、 B木はノードの中で線形探索を行います。当然その分遅くなるわけです。 (※ ノードの中でも 2分探索を行い、性能を改善するB木 のバージョンもあります。 B木の要素はノードの中で整列していますので2分探索可能です)
では何故、 わざわざ多分木などという面倒くさいことをしてまでB木を使うのでしょう? ここで枝をたどるコストが極端に高い場合を想像してみてください。 例えば比較のコストに比べて1000倍くらいかかると考えます。 すると多少の比較回数は枝をたどることに比べれば無いに等しくなります。 つまり、カウントされるコストは枝をたどる回数だけということになります。 B木の方が有利になるわけです。
ハードディスクなど遅いブロックデバイス上に探索木を展開した場合、 まさに枝をたどるコストが支配的になります。 B木はこうしたデバイスと組み合わせて使うときにその真価を発揮します。 さらに、B木はブロックデバイスに都合の良い特徴を持っています。 それはノードの中にたくさんの要素を保持しているということです。 ブロックデバイスはアクセスは遅いですが、 一度に読み込むデータ量は多くなります。 つまり、B木のノードが保持する要素の数とブロックデバイスのブロック長をうまく合わせてやれば、 非常に効率よく各要素にアクセスできることになるわけです。